Lors des Olympiades Internationales de Mathématiques, Google DeepMind et OpenAI ont tous deux annoncé que leurs modèles d'IA avaient atteint le niveau médaille d'or, résolvant chacun 5 des 6 problèmes les plus difficiles de la compétition.
Google DeepMind précise que "une version avancée de Gemini Deep Think a résolu parfaitement cinq des six problèmes IMO, obtenant 35 points au total et atteignant le niveau médaille d'or".
Cette performance a même impressionné les organisateurs : le président de l'IMO, confirme que "Google DeepMind a atteint le jalon tant désiré, obtenant 35 points sur 42 possibles — un score médaille d'or. Leurs solutions étaient étonnantes à bien des égards. Les correcteurs les ont trouvées claires, précises et pour la plupart faciles à suivre".
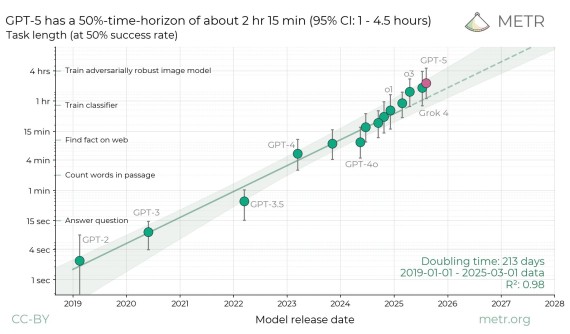
Cependant, une étude indépendante de MathArena révèle un écart immense entre les capacités des modèles expérimentaux et ceux accessibles au public.
Tandis que les systèmes les plus avancés atteignent l'excellence, Gemini 2.5 Pro (le meilleur modèle public testé) n'obtient que 31% (13/42 points). Tous les autres modèles publics testés échouent avec moins de 10% de bonnes réponses.
Cette asymétrie, entre les modèles disponibles au public et les modèles les plus avancés, est problématique car elle rend très difficile l'évaluation indépendante des risques et des capacités réelles de l'IA.
De plus, il devient presque impossible pour les chercheurs et les régulateurs d'anticiper les évolutions des modèles d'IA les plus avancés.
Même les développeurs sont surpris par leurs propres percées.
Comme l'avoue Noam Brown d'OpenAI :
"Quand on travaille dans un laboratoire de pointe, on connaît généralement les capacités [des modèles frontières] des mois à l'avance. Mais ce résultat est tout nouveau... Ça a surpris même beaucoup de chercheurs chez OpenAI".
|